
The customs agent pauses with the passport stamp in his hand and asks what my business in Canada is. “I’m going to a conference, the AMTA, Association of Machine Translation in the Americas,” I say. “You’re late,” he tells me, snapping the stamp downwards. This is the first time any customs agent has even heard of the conferences I go to, so I nod and then slink away past him into Canada, feeling chastised and amused both at once.
I’m attending the AMTA as a localization professional, but my globe-trotting self has a pressing question: is it ever going to be possible to have a reliable, accurate machine-translation (MT) travel voice-recognition and text-reading app for all your daily communication needs in far-flung locales?
MT combines linguistics, coding and even mathematics. At the AMTA, I keep thinking: this is a homeschooler’s paradise, where the super-nerds could really excel and maybe even make money from being super nerdy. If you could corner the market on accurate MT, you’d be rich. I wear my super-nerd-trying-to-be-cool uniform of an artisanal T-Rex tshirt purchased at the Portland Saturday Market from ARTjaden. And then a somber gray wool cardigan to button up over it in case it’s too casual.
Nearly all of the presentations at the AMTA deal with corporate or governmental MT: which engines work with which languages, which subject matter, which approach, how many errors are Ok in what kinds of documents. Also, how to train linguists to be corporate MT post-editors, and how to feed their improvements back into the MT engine so it learns how to translate better.
MT is incredibly complex because language is incredibly complex. For a language pair like French-English, something like Google Translate works reasonably well, reasonably being the operative word. First, because the languages are similar in terms of grammar and vocabulary. Second, because a huge amount of text already exists in parallel French and English iterations. There’s a whole slew of English source texts and French translations, and vice versa. This means that when something like the Google translation engine is learning how you are supposed to translate “Bob’s your uncle,” it can approximate pretty accurately from the million or so similar examples previously translated by real humans. Google is a statistical machine translation engine, meaning that behind its machinations, it learns basically how babies learn: by rote, by observation. Or perhaps I should say, how second-language learners learn. Like many second language learners, statistical machine translation engines may err on the side of taking things too literally.
Here’s why literal translation may not work. A guy behind me this morning cheerfully says to the speaker, who’s about to go on: “Je te dis merde.” She’s horrified; she must understand some French, and asks “why would you say that to me?” He responds: “It means break a leg,” but she still doesn’t understand. Since I’m physically in the middle of them anyway, I translate the two idioms: “it means good luck, but you’re not supposed to say good luck.” She’s relieved, and tells the French-speaker thank you. Ironically, her presentation is about how to code semantics with rule-based engines so that mistranslations like this don’t happen.
Now I’m curious, so I look this phrase up on Google Translate.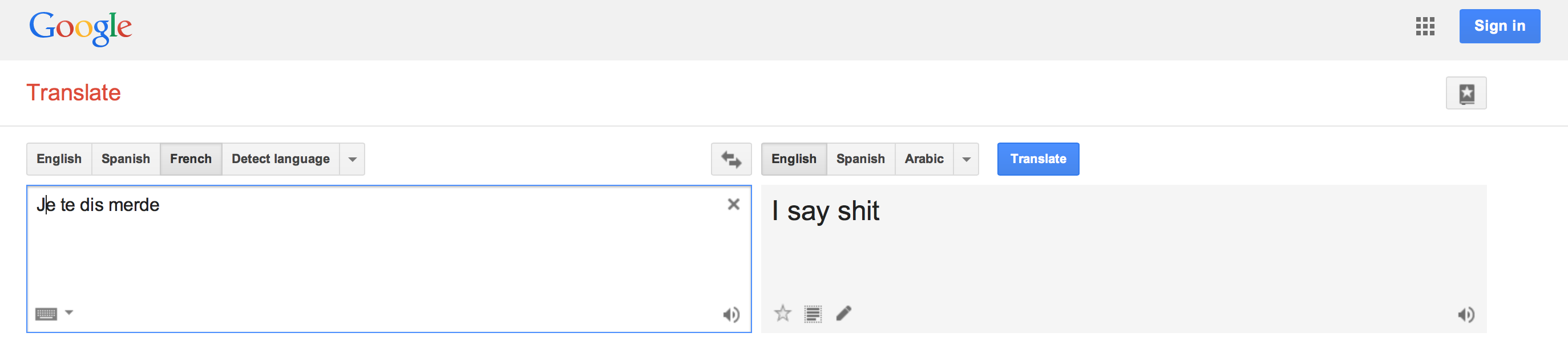
Nonetheless, a properly trained pocket French-English statistical machine translator might not be that bad, as long as it could access the cloud and the enormous of data it would need to run effectively. Something like Swahili-English, not so much. Swahili is too grammatically complex, too dissimilar to English, and very little parallel data exists on the web for it. You’d need to build a rule-based system for it, and spend a fair amount of time training the engine.
I keep an ear open for it, but nobody in the private or public sectors at this conference specifically mentions developing MT apps for backpackers; the conference focused mainly on scenarios for more accurate translation, complete with mathematical formulas and heavy use of acronyms, such as “C API used for BASIS Language ID, rather than SOAP-based API.” One person did bring up having apps for tourists, and suggested having different apps for different scenarios, such as a specific terminology-oriented app for the doctor’s office. As everyone in MT knows by now, training engines for domain-specific, limited usage is way more accurate than when you throw hundreds of idiomatic expressions together into computational soup. So, in case this wasn’t already obvious, if you’re relying on Google Translate for your foreign doctor’s visit, that’s a terrible idea.
However, all this behind-the-scenes research and development may one day trickle down into cheap portable commercial MT paired with voice recognition, and the way things are looking, it may only be five years or so before this is a reality. Note: this is what people have been saying about MT since about 1955.
